검색결과 리스트
분류 전체보기에 해당되는 글 810건
- 2025.07.15 AI로 뭐하지?
- 2025.06.18 가계도 그리기 웹앱 v2.0 3
- 2025.06.18 생태도 그리기 웹앱 v2.2 1
- 2025.06.17 생태도 그리기 웹앱 v1.1 1
- 2025.06.12 가계도 그리기 웹앱 v1.1 1
글
AI로 뭐하지?
사회복지사의 AI 활용을 돕는 사이트를 만들었습니다.
사회복지사의 AI 활용
https://bit.ly/ai4welfare
sites.google.com
Smart Welfare Tech: 사회복지사의 AI 활용 및 실무 도구
현장의 고민을 기술로 해결하는 사회복지사 정수홍의 AI 워크플로우 및 디지털 도구 모음집입니다.
thornjsh.github.io
위 둘은 결국 같은 사이트입니다.
세부적인 하위 페이지 목록은 다음과 같습니다.
- 홈
- 스마트복지기술
- 스마트워크
- 구글 스프레드시트
- DX 스프레드 시트 예제
- DX Docs 매뉴얼
- AI 활용 강좌
- 부산 스마트복지 실천기관
- 열매똑똑 아이디어 HUB
- 바이브 코딩(철학)
- 바이브 코딩(활용팁)
- 사회복지사를 위한
- 가계도 그리기
- 생태도 그리기
- GPS를 활용한 출퇴근관리
- PDF 플립북
- 표 스타일 정리 도구
- 후원신청서
- 사회복지시설 공통업무 캘린더
- With AI
- AI Prompt Pro
- SNS 홍보문 만들기
- 문서 타당성 검토
- 인권 지향적 글쓰기
- Docs에서 AI 쓰기
- Sheet에서 AI 쓰기
- Slide에서 AI 쓰기
- Gemini로 PPT 만들기
- 후원 전략 컨설팅
- 챗봇, Chatbot
- Ct 정서 예측 모델
- Mini App
- 윈도우 시계 설정
- 시간조건 파일 복사
- 엑셀 비밀번호 일괄변경
- PDF MultiTool
- 법령 조문(키워드) 검색
- 통계다루기
- 기초 통계 분석
- 사전-사후 비교
- IPA 분석(Excel)
- 이런 것도 가능해요
- [게임] 아기하마 구하기
- 크리에이티브 쇼케이스
- FAQ
- 초기설정(권한 설정)
- 사본 만들기
- API 키 만들기
- 구글 클라우드 설정
- Q&A (질문과 답변)
'[楞嚴] 생각 나누기 > [報] AI로 뭐하지?' 카테고리의 다른 글
| 생태도 그리기 프로그램 (0) | 2025.11.29 |
|---|---|
| 가계도 그리기 프로그램 (0) | 2025.11.29 |
| [웹앱] 생태도 그리기 (0) | 2025.07.15 |
| 스마트 복지 기술이란? (0) | 2025.07.15 |
설정
트랙백
댓글
글
가계도 그리기 웹앱 v2.0
가계도 그리기 프로그램
구글 Antigravity를 사용해 바이브코딩으로 만든 가계도 그리기 프로그램입니다.다운받아서 바로 실행하실 수 있습니다. 업로드 용량 제한으로 GitHub를 통해 배포합니다. https://github.com/ThornJSH/FamilyT
welfareact.net
윈도우용 실행 프로그램이 더 익숙하실 듯하여 최종적으로 위 링크로 대체합니다.
--웹앱에 대한 정보는 아래에 있습니다.--
기존의 가계도 그리기 웹앱에서 저장 기능을 추가하였습니다.
- 본인이 그린 가계도의 목록을 선택해 불러올 수 있습니다.
- 마찬가지로 삭제도 가능합니다.
- 특정 인물을 클릭하고 그것만 삭제하는 것도 가능합니다.
그리고 보다 다양한 가족관계를 구현 가능하게 만들었습니다.
- 이혼, 별거 등 결혼관계 추가
- 입양자녀 표기 추가
- 반려동물 입력 추가
또한 이미지로 저장하는 방식도 다양화했습니다.
- JPG 저장: 배경이 흰색 이미지로 저장됩니다.
- PNG 저장: 배경이 투명한 이미지로 저장됩니다.
다만, 아직 쌍둥이는 제대로 구현하지 못하고 있습니다.
추후 개발 목표로 삼아야 할 것 같습니다. (현재 새버전에서 구현 됩니다.)
이번에도 Google AI Studio를 활용해 만들었습니다.
아래 링크에서 확인해보세요.
새버전을 만들었습니다.
현재 버전은 2.8입니다. 아래 링크를 이용하세요.
단, 처음 사용시에는 권한설정을 해주셔야만 합니다.
2025.06.18 - [[楞嚴] 생각 나누기/[情] 사회복지정보화] - 생태도 그리기 웹앱 v2.1
권한설정방법은 위 링크를 참조하세요.
한편 이런 앱 개발은 바이브 코딩이라는 방식을 통해서 만들고 있습니다.
활용한 프롬프트를 공유해드리니 개발 시도하실 분은 아래 프롬프트를 참고해서, 확장해나가시는 것도 방법이 되지 않을까 합니다.
https://docs.google.com/document/d/1ISf41EzknqR3eUwoUUxPVjJGgPvL8KuOhDmCKWU3pv4/edit?usp=sharing
가계도 웹앱 만들기 프롬프트
당신은 지금부터 구상 가능한 최고의 구글 Apps Script 웹앱 개발자입니다. 이번에 새로운 프로젝트로 구글 스프레드 시트, 구글 Apps Script, HTML/SVG를 조합하여 **"가계도 그리기 웹앱"**을 제작합니다
docs.google.com
'[楞嚴] 생각 나누기 > [情] 사회복지정보화' 카테고리의 다른 글
| 근태관리대장 (0) | 2026.02.11 |
|---|---|
| 사회복지사의 AI 활용 (0) | 2026.02.05 |
| 생태도 그리기 웹앱 v2.2 (1) | 2025.06.18 |
| 생태도 그리기 웹앱 v1.1 (1) | 2025.06.17 |
| 가계도 그리기 웹앱 v1.1 (1) | 2025.06.12 |
설정
트랙백
댓글
글
생태도 그리기 웹앱 v2.2
생태도 그리기 프로그램
구글 Antigravity를 사용해 바이브코딩으로 만든 생태도 그리기 프로그램입니다.다운받아서 바로 실행하실 수 있습니다. 업로드 용량 제한으로 GitHub를 통해 배포합니다. https://github.com/ThornJSH/EcoMap
welfareact.net
윈도우용 실행 프로그램이 더 익숙하실 듯하여 최종적으로 위 링크로 대체합니다.
--웹앱에 대한 정보는 아래에 있습니다.--
최초 버전에서는 불가능했던 생태도 저장 문제를 해결했습니다.
그외 자잘한 편의가 추가되었구요~
이번엔 claude가 아니라 Google AI Studio를 활용했습니다.
주어지는 토큰이 훨씬 많아, 개발 오류를 해결하는데 훨씬 도움이 되었습니다.
주요변화라면,
1. 저장이 가능합니다. 따라서 불러오기도 됩니다.
이 기능이 필요했던 건, Apps Script를 잘 모르시는 분들이 사본만들기 하시는 번거로운 과정을 생략할 수 있기 때문입니다.
단, 구글 계정에 로그인해 있어야 합니다. 최소한의 장치입니다.
2. 이미 그린 생태도의 관계를 선택한 후 delete 키로 삭제가 가능합니다.
처음부터 다시 그려야하는 번거로움이 줄었습니다.
3. 관계에 있어 갈등관계를 표현하는 선의 모양이 바뀌었습니다.
화살표 모양의 처리도 조금 달라졌습니다. 사용하는 코드의 소스가 다릅니다.
4. 만들어진 생태도를 jpg로도 png로도 저장할 수 있습니다.
jpg 이미지는 배경이 흰색입니다. 하지만 png는 배경이 투명입니다.
용도에 따라 맞게 다운로드하시면 됩니다.
update. 2025. 6. 23.-----------------------------------------------------------------------
갈등관계를 나타내는 선을 물결모양에서 뽀족한 모양으로 변경했습니다.
--------------------------------------------------------------------------------------------------
참고로 처음 사용시, 사용자의 구글 계정 ID를 확인합니다.
권한 허용을 해주셔야만 사용하실 수 있습니다.






혹시나 따라하실 분을 위해 프롬프트도 제공해드립니다.
https://docs.google.com/document/d/1TMp371bQ7G6ZAPuz6ookG8_S7dO5SafINV19tTRpr2w/edit?usp=sharing
생태도 웹앱 만들기 프롬프트
당신은 지금부터 지상 최고의 구글 Apps Sciprt 웹앱 개발자입니다. 이번에 새로운 프로젝트로 구글 스프레드 시트, 구글 Apps Script, html/canvas 또는 SVG 조합으로 "생태도 그리기 웹앱"을 만드려합니다
docs.google.com
'[楞嚴] 생각 나누기 > [情] 사회복지정보화' 카테고리의 다른 글
| 사회복지사의 AI 활용 (0) | 2026.02.05 |
|---|---|
| 가계도 그리기 웹앱 v2.0 (3) | 2025.06.18 |
| 생태도 그리기 웹앱 v1.1 (1) | 2025.06.17 |
| 가계도 그리기 웹앱 v1.1 (1) | 2025.06.12 |
| PDF에 비밀번호 설정하기 (0) | 2025.05.28 |
설정
트랙백
댓글
글
생태도 그리기 웹앱 v1.1
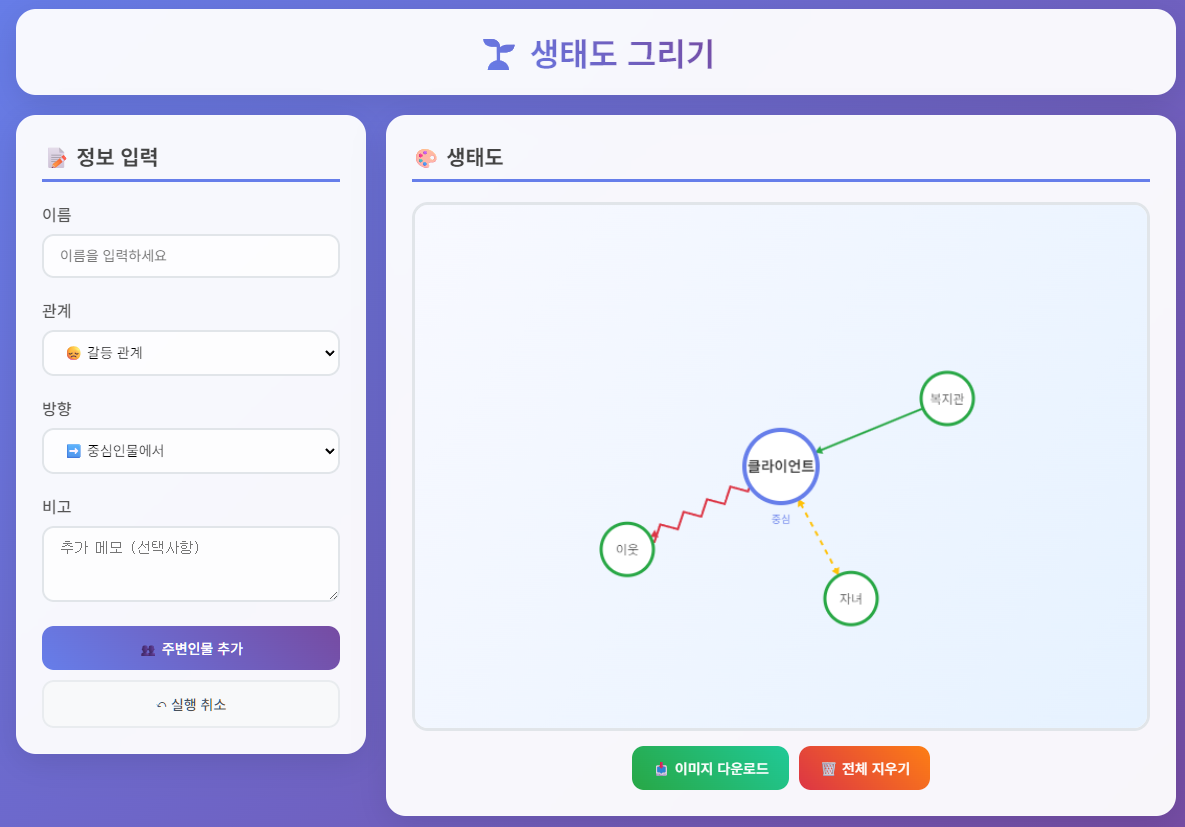
생태도 그리기 프로그램
구글 Antigravity를 사용해 바이브코딩으로 만든 생태도 그리기 프로그램입니다.다운받아서 바로 실행하실 수 있습니다. 업로드 용량 제한으로 GitHub를 통해 배포합니다. https://github.com/ThornJSH/EcoMap
welfareact.net
윈도우용 실행 프로그램이 더 익숙하실 듯하여 최종적으로 위 링크로 대체합니다.
--웹앱에 대한 정보는 아래에 있습니다.--
https://script.google.com/macros/s/AKfycbxaq0DbFskQ4bVNsF5bbqeLiSROL0yszlm86fz4QCtMf7xMrMR8t21joMPDxbdTahE/exec
script.google.com
클릭하시면 바로 실행해 보실 수 있습니다.
소스 코드를 보시려면 아래 링크를 클릭하세요.
Google Drive: 로그인
이메일 또는 휴대전화
accounts.google.com
가계도와 마찬가지로 Claude.ai를 기본으로 했습니다.
이때 사용된 프롬프트는 다음과 같습니다.
| 당신은 지금부터 지상 최고의 구글 Apps Sciprt 웹 앱 개발자입니다. 이번에 새로운 프로젝트로 구글 스프레드 시트, 구글 Apps Script, html/canvas 또는 SVC 조합으로 "생태도 그리기 웹앱"을 만드려합니다. 앱 주요 기능과 사용자 흐름은 다음과 같습니다. == [앱 주요 기능] 시작 == 1. 사용자가 웹에서 생태도를 그리는 웹 앱을 만들고 싶습니다. 2. 사용자는 중심인물과 주변인물, 그리고 중심인물과 주변인물의 관계를 웹에서 입력하면, 앱스 스크립트를 통해 생태도로 전환해 보여줍니다. 3. 만들어진 생태도는 이미지로 저장할 수 있습니다. == [앱 주요 기능] 끝 == == [사용자 흐름] 시작 == 1. 웹에서 생태도를 그릴 중심인물의 데이터를 입력합니다. 2. 중심인물을 중심으로 주변인물 또는 조직의 의 관계를 입력합니다. - 이름 - 관계: 좋은 관계, 소원한 관계, 갈등 관계 - 방향: 중심인물을 중심으로 화살표가 밖으로 향하는지, 안으로 향하는지, 양방향인지 3. 생태도 자동 그리기: 시트 데이터를 기반으로 canvas에서 자동 배치 4. 클릭 조정: 만들어진 도형은 마우스 드래그로 위치 조정 5. 실행 취소를 통해 이전단계로 돌아가는 기능 6. 이미지 저장: 캔버스를 png로 다운로드 7. 데이터 삭제: 저장된 데이터를 삭제해서 생태도를 초기화(빈 캔버스) == [사용자 흐름] 끝 == == [백엔드 구성] 시작 === 1. 필드 구조 : 이름, 관계, 방향, 비고 == [백엔드 구성] 끝 === == [화면 인터페이스 구성] 시작 == 화면은 두 개의 영역으로 구분됩니다. 1. 1영역은 생태도를 그리고자 하는 사람의 정보를 입력하는 영역 먼저 중심인물을 입력합니다. 이후 주변인물의 정보를 입력합니다. 이때 중심인물과의 관계를 선택 입력합니다. 관계는 좋은 관계, 소원한 관계, 갈등 관계을 선택할 수 있습니다. 2. 2영역은 입력된 정보가 구현되어 보여지는 영역입니다. - 중심인물과 주변인물은 원(<circle>)으로 구현합니다. 이때 도형 안의 색깔은 흰색으로 합니다. - 입력된 중심인물과 주변인물의 관계를 선으로 연결: 좋은 관계는 실선, 소원한 관계는 점선, 갈등 관계는 지그재그 선으로 표현 - 완성된 도형은 마우스로 클릭하고 드래그 해서 수평, 수직 이동이 가능해야합니다. 이때 이미지나 선 모양의 변형은 없어야 합니다. - 실행 취소를 통해 마지막에 입력한 인물을 지울 수 있어야 합니다. - 생태도가 구현이 되면, 이를 이미지로 저장(다운로드)할 수 있는 버튼이 있습니다. == [화면 인터페이스 구성] 끝 == == [추가 요청] 시작 == - 모든 개발은 구글 Apps Script + HTML/CSS/JS 로 진행합니다. - Code.gs, index.html, styles.html, script.html 각각의 역할별로 코드를 만들어주세요. - 만드는 코드의 길이가 지나치게 길어지지 않도록 최적화 해주세요. - 최신 트렌드에 맞춰서 세련된 디자인으로 꾸며주세요. == [추가 요청] 끝 == |
'[楞嚴] 생각 나누기 > [情] 사회복지정보화' 카테고리의 다른 글
| 가계도 그리기 웹앱 v2.0 (3) | 2025.06.18 |
|---|---|
| 생태도 그리기 웹앱 v2.2 (1) | 2025.06.18 |
| 가계도 그리기 웹앱 v1.1 (1) | 2025.06.12 |
| PDF에 비밀번호 설정하기 (0) | 2025.05.28 |
| 구글 Apps Script로 후원신청서 만들기 (3) | 2024.09.30 |
설정
트랙백
댓글
글
가계도 그리기 웹앱 v1.1
가계도 그리기 프로그램
구글 Antigravity를 사용해 바이브코딩으로 만든 가계도 그리기 프로그램입니다.다운받아서 바로 실행하실 수 있습니다. 업로드 용량 제한으로 GitHub를 통해 배포합니다. https://github.com/ThornJSH/FamilyT
welfareact.net
윈도우용 실행 프로그램이 더 익숙하실 듯하여 최종적으로 위 링크로 대체합니다.
--웹앱에 대한 정보는 아래에 있습니다.--
AI를 활용해서 가계도를 그리는 웹앱을 개발해보았습니다.
이를 위해 구글 스프레드 시트, 구글 Apps Script가 활용되었습니다.
실행은 아래 링크를 통해 바로 테스트해보실 수 있습니다.
단, 개인사용자를 위해 만들었기 때문에 사본만들기를 통해 개인계정에 등록하고 사용해주시면 감사하겠습니다.
사본은 아래 구글 스프레드 시트에서 사본만들기 하시면 됩니다.
https://docs.google.com/spreadsheets/d/1383VpKg63M2MaTRnm5VIP9_AJRWTqX7YBO1Av78sE8A/edit?gid=0#gid=0
이후 스프레드 시트 ID를 사용해 Code.gs를 본인의 것으로 수정해주시면 됩니다.
'[楞嚴] 생각 나누기 > [情] 사회복지정보화' 카테고리의 다른 글
| 생태도 그리기 웹앱 v2.2 (1) | 2025.06.18 |
|---|---|
| 생태도 그리기 웹앱 v1.1 (1) | 2025.06.17 |
| PDF에 비밀번호 설정하기 (0) | 2025.05.28 |
| 구글 Apps Script로 후원신청서 만들기 (3) | 2024.09.30 |
| Apps Script를 활용해 스프레드 시트로 데이터 전송하기 (0) | 2024.09.23 |

RECENT COMMENT